1. Введение
1.1. Соображения по формату листингов
Алгоритмы и структуры данных фундаментальны, их применимость слабо зависит от используемого языка программирования. Поэтому в рамках данного руководства будут использоваться листинги на псевдокоде. За основу синтаксиса псевдокода взят Python из-за его краткости и знакомости студентам начальных курсов. Некоторые отличия используемого синтаксиса:
- В том числе Си-подобный синтаксис циклов
forиwhile, но с опциональным указанием скобок для консистентности с Python; - Операторы инкремента и декремента (например,
i++вместоi += 1); - Опциональная типизация, указание типа
Anyтам, где тип не имеет значения; - Где уместно абстрагирование от сигнатур и большая высокоуровневость, используется естественный язык.
1.2. Особенности выполнения алгоритмов
Алгоритм – это конечная последовательность инструкций исполнителю, в результате выполнения которых обеспечивается получение из входных данных требуемого выходного результата (решение задачи). Для любой задачи возможно придумать большое число алгоритмов решения, в связи с чем встаёт вопрос о выборе подходящего в каждом конкретном случае. На выбор могут влиять такие метрики как: простота реализации, понятность, универсальность, компактность, простота отладки и многие другие. В рамках данного курса мы в большей степени концентрируемся на технических метриках: временной эффективности и необходимых затратах по памяти. Однако в реальной практике разработки ПО важную роль играют и другие критерии, зависящие от требований заказчика, удобства сопровождения, предпочтений команды и прочего. Поэтому не существует «лучшего» алгоритма на все случаи жизни.
Даже с точки зрения только технических характеристик (время и память) выбор может быть неоднозначным. Результаты сильно зависят от таких факторов, как: размер входных данных, особенности конкретной реализации, производительность компьютера (его процессора, памяти), архитектура процессора, число ядер, особенности среды выполнения и т.д. Поэтому на практике важно сравнивать алгоритмы экспериментально в условиях, приближенных к реальному использованию. Это называется бенчмаркингом. В ходе него сравниваемые алгоритмы многократно запускаются на одинаковых данных с замерами необходимых метрик (в первую очередь, времени выполнения) и усреднением. О подходах к теоретическому анализу же, абстрагируясь от конкретики ситуации, будет сказано в следующей главе. Однако, стоит не забывать, что теоретический и практический анализ должны дополнять друг друга.
Одним из наиболее влиятельных факторов производительности алгоритма или программы является среда выполнения. Она также определяет подходы к проведению бенчмаркинга. Языки программирования (а если быть точным, их среды выполнения) можно условно разделить на три категории: компилируемые, на основе виртуальной машины и интерпретируемые.
Исходный код программы на компилируемом языке (C, C++, Rust, Go, Zig) подаётся на вход программе-компилятору, которая транслирует его в машинные команды, непосредственно исполняемые затем при запуске полученного файла. Все возможные оптимизации производятся на этапе компиляции. Такие программы наиболее быстры, а при практическом исследовании их эффективности не нужно соблюдать каких-либо дополнительных правил.
Исходный код программы на Java, C#, Elixir, Kotlin компилируется в промежуточный байт-код, исполняемый затем виртуальной машиной при запуске программы. Такой подход обеспечивает кроссплатформенность скомпилированной программы, позволяет производить дополнительные оптимизации уже в процессе выполнения, а также производить JIT-компиляцию (Just in Time, компиляция «точно в нужное время») для дополнительного ускорения. Из-за этого при экспериментальных замерах производительности необходимо делать прогрев (warmup): дать виртуальной машине многократно выполнить интересующий код, совершив все возможные оптимизации и стабилизировав производительность, и только затем осуществлять замеры (всё это на одном запуске программы).
Наконец, исходный код программы на интерпретируемом языке (Python, Ruby, PHP, JS) разбирается и сразу непосредственно выполняется программой-интерпретатором. Этот подход наиболее медленный, но позволяющий добиться максимально высокого уровня абстрагирования. Интерпретаторы могут заменять некоторые механизмы операционной системы вроде своей реализации стека. Другая важная особенность – наличие, как правило, GIL (Global Interpreter Lock), глобальной блокировки на выполнение в рамках одного процесса интерпретатора более одного потока команд. Это усложняет распараллеливание вычислений. Практически во все актуальные интерпретаторы в том или ином виде также внедряются элементы JIT, из-за чего при бенчмаркинге требуется соблюдать те же правила прогрева, что и для языков на виртуальной машине.
Среди прочих внешних факторов, влияющих на производительность алгоритмов, важно выделить особенности процессора. Например, при чтении условных 4 байт из оперативной памяти фактически загружается значительно больший кусок (обычно 64 байта), который сохраняется во внутренней временной памяти процессора – кеше. Если затем понадобится значение, содержащееся в этих данных, оно будет считано из кеша и не произойдёт обращения к гораздо более медленной оперативной памяти. Поэтому последовательное размещение и обработка данных (например, в массивах) часто оказывается значительно эффективнее случайного доступа. Другой механизм ускорения, доступный при последовательном размещении – параллельные инструкции (SIMD-инструкции), присутствующие во многих процессорных архитектурах. Они позволяют выполнить арифметическую или логическую операцию для нескольких пар последовательно размещённых значений за одну команду процессора. Некоторые компиляторы могут сами определять возможность использования подобных инструкций, но обычно их задействование требует явных усилий программиста при написании кода.
Для повышения производительности можно использовать многопоточность или многопроцессность, задействуя несколько ядер процессора. Однако помимо ряда неизбежных трудностей главная проблема заключается в том, что абсолютное большинство алгоритмов в значительной степени требуют соблюдения последовательности шагов. Из-за этого лишь некоторые этапы могут быть эффективно распараллелены и требуется использование инструментов синхронизации потоков/процессов. Поэтому эффект на производительность может быть не столь значительным. Впрочем, многие алгоритмы обработки изображений, обучение нейросетей и ряд других повсеместных задач вполне эффективно разбиваются на отдельные независимые подзадачи, позволяя выжать максимум производительности. Как правило, такие алгоритмы выполняют даже не на ядрах процессора, а на графических ускорителях (GPU), обладающих на порядки большим числом слабых вычислительных блоков.
При рассмотрении рекурсивных алгоритмов необходимо учитывать дополнительный фактор, влияющий на их применимость. Как известно, рекурсивные функции – это функции, вызывающие сами себя. А при каждом вызове подпрограммы перед переходом на участок памяти, содержащий её инструкции, необходимо сохранить адрес возврата. Подобные адреса, а также аргументы вызова, локальные переменные и некоторая другая информация хранятся в так называемом стеке вызовов или системном стеке. Под подобный стек в оперативной памяти выделяется участок памяти для каждого потока. В случае возврата из подпрограммы стек уменьшается. При этом максимальный его размер ограничен. В связи с этим при слишком большой глубине рекурсии есть риск ошибки переполнения или «Stack overflow». Поэтому в общем случае нерекурсивные реализации алгоритмов предпочтительнее. Хотя некоторые компиляторы умеют оптимизировать так называемую хвостовую рекурсию (когда рекурсивный вызов является последней операцией перед возвратом), транслируя её в обычный итеративный код.
1.3. Структуры данных. Абстрактный тип данных
Помимо примитивных типов данных (целое, булево значение, символ и т.д.) большинство языков программирования позволяют создавать пользовательские составные типы и определять операции над ними. Такие типы и называют структурами данных. Совокупность функций (методов), реализующих операции над структурой данных, называется ее интерфейсом.
Наряду с понятием структуры данных используется более общее понятие абстрактного типа данных (АТД). Абстрактный тип данных – это концептуальное описание структуры данных, определяемое её назначением и интерфейсом. Иными словами, АТД задаёт что должна уметь делать структура, не привязываясь к тому, как она реализована. Один и тот же АТД может иметь множество различных реализаций, отличающихся способами хранения данных и алгоритмами выполнения операций. Примеры АТД: список, стек, очередь, очередь с приоритетом, словарь, граф. В последующих разделах будут рассмотрены различные способы реализации этих структур.
Все структуры данных, помимо прочего, можно разделить на статические и динамические. Статические структуры данных имеют фиксированный размер, задаваемый заранее и не изменяющийся во время выполнения программы. Пример – обычный статический массив. Динамические структуры, напротив, могут изменять свой размер во время работы программы. Это достигается либо путём перевыделения памяти (например, в динамическом массиве), либо с помощью управления отдельными элементами, связанными между собой ссылками или указателями (переменными, хранящими адрес связанного элемента в памяти). На практике элементы динамических структур обычно реализуются в виде объектов классов или структур, содержащих поля-ссылки на другие элементы. Эти объекты создаются и удаляются в процессе работы программы, образуя связанную систему.
К примеру, для простейшей реализации в памяти односвязного списка достаточно определить структуру узла следующим образом:
class ListNode:
data: any
next: ListNode
Здесь data – значение элемента, next – ссылка на следующий элемент. Для работы со списком достаточно иметь ссылку на первый элемент, называемый головой списка. Доступ к остальным элементам осуществляется путём последовательного перехода по ссылкам next (последовательный доступ). У последнего элемента ссылка next равна None, что указывает на конец последовательности. Для полной реализации списка необходимо реализовать функции вставки, удаления, поиска и другие операции. Все они будут заключаться в инициализации или высвобождении памяти под узлы, а также различных манипуляциях со ссылками. Например, вставка в связный список после указанного элемента:
def insert_after(node, data):
new_node = ListNode(data)
new_node.next = node.next
node.next = new_node
return new_node
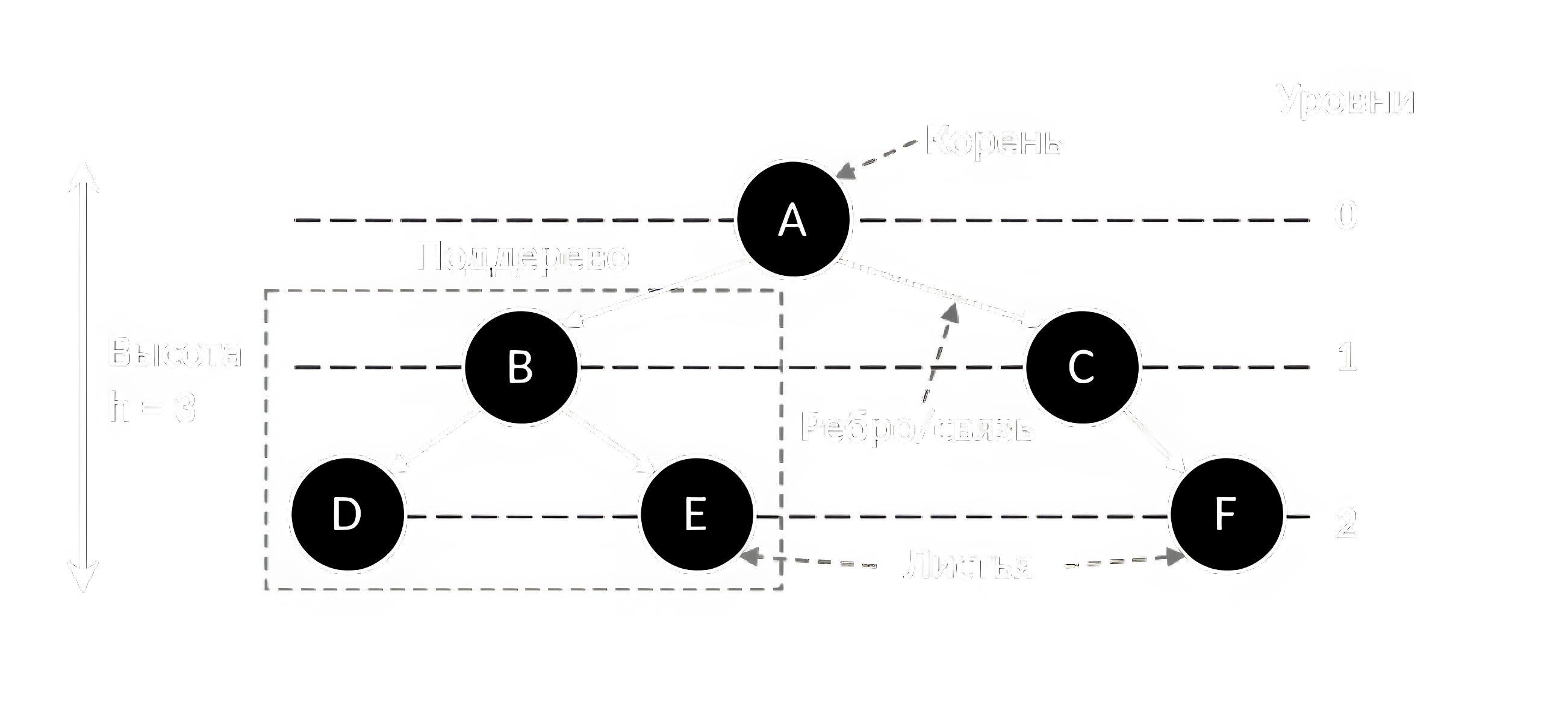
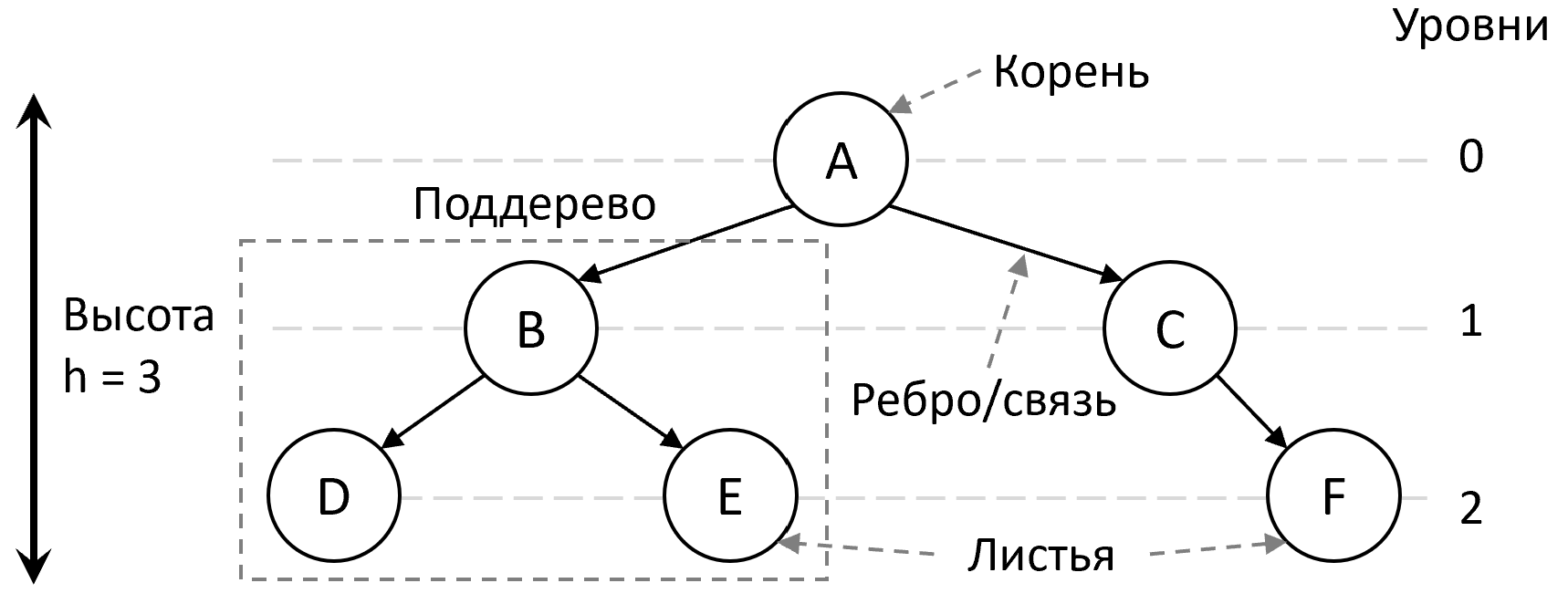
Односвязный список является примером линейной структуры данных. Среди нелинейных структур данных можно выделить графы, где связи могут быть установлены между произвольными узлами (вершинами), и их частный случай – деревья. В деревьях отсутствуют циклы, указан начальный корневой узел, и в каждой связи один узел является родителем, а другой – потомком (ребёнком). Основные понятия, используемые для описания деревьев указаны на рисунке 1.